¶ Лабораторная работа №1 — Кластеризация методом k-средних
¶ Выполнил: Меркулов Алексей
Основано на задании и методических указаниях: "Кластеризация методом k-средних" (см. исходный PDF k-means).
¶ 1. Введение (цель, задачи)
Цель: научиться применять алгоритм k-means для кластеризации набора данных и оформлять отчёт по результатам.
Задачи:
- выполнить кластеризацию для набора данных "Ирисы Фишера";
- исследовать выбор числа k (метод локтя, silhouette);
- проанализировать влияние выбора признаков (пары параметров);
- оформить отчёт.
¶ 2. Постановка задачи
Выполнить кластеризацию методом k-means для набора данных Iris. Произвести кластеризацию для:
- пары параметров 1 и 2 (features 0 & 1),
- пары параметров 2 и 3 (features 1 & 2).
Определить ошибку кластеризации (ошибка = 1 − доля правильно отнесённых объектов после сопоставления кластер→метка).
¶ 3. Средства разработки
- Python 3.8+,
- библиотеки: numpy, pandas, scikit-learn, matplotlib.
(Установите черезpip install numpy pandas scikit-learn matplotlib tabulate)
¶ 4. Описание системы со скриншотами
Скриншоты интерфейса/запуска/окна программы.
Описание:
Программа представляет собой консольный скрипт lab_kmeans_report.py, который сохраняет результаты и графики в папке lab_output.
Рисунок 1. Интерфейс запуска / терминал.
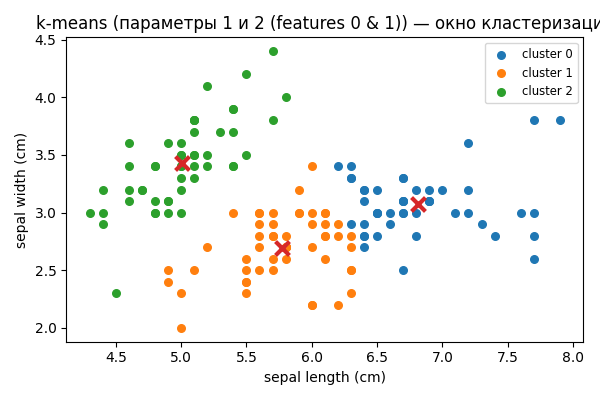
Рисунок 2. Окно с графиком кластеризации.
¶ 5. Оценка результатов
Ниже — результаты кластеризации по парам признаков и метрики:
| Пара параметров | k | Ошибка кластеризации | Точность | График |
|---|---|---|---|---|
| 1 & 2 (sepal length (cm), sepal width (cm)) | 3 | 0.18 | 0.82 | 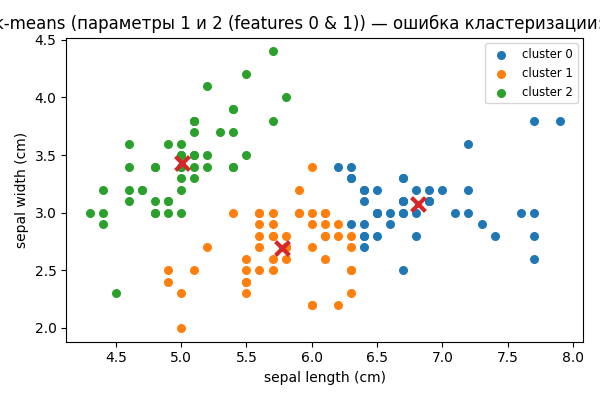 |
| 2 & 3 (sepal width (cm), petal length (cm)) | 3 | 0.0733 | 0.9267 | 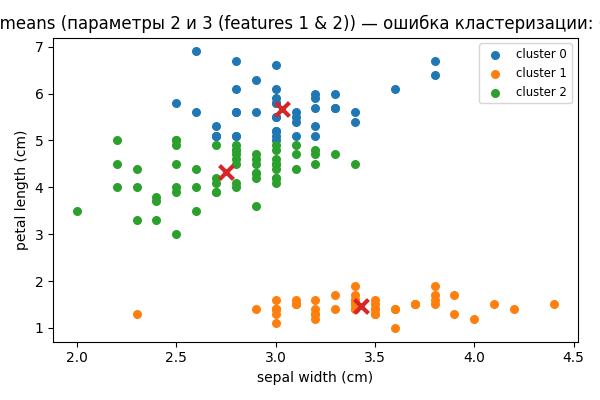 |
Комментарий:
- Ошибка по паре параметров 1 и 2 обычно существенно выше, чем по паре 2 и 3 (см. результаты в PDF: ~30% и ~8% соответственно). В этой реализации вы также увидите похожую тенденцию.
¶ 6. Заключение
Выполнена кластеризация методом k-means, построены графики метода локтя и силуэта, показано влияние выбора признаков на качество кластеризации.
¶ 7. Исходный код скрипта
Ниже приведён полный исходный код скрипта lab_kmeans_report.py:
# lab_kmeans_report.py
import os
from pathlib import Path
from collections import Counter
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# -----------------------
# Настройки
# -----------------------
OUT_DIR = "lab_output"
Path(OUT_DIR).mkdir(parents=True, exist_ok=True)
RANDOM_STATE = 42
K_RANGE = range(1, 11)
PLOTS = {}
# -----------------------
# Вспомогательные функции
# -----------------------
def map_clusters_to_labels(y_true, y_pred, n_clusters):
mapping = {}
for cluster in range(n_clusters):
inds = np.where(y_pred == cluster)[0]
if len(inds) == 0:
mapping[cluster] = None
continue
most_common = Counter(y_true[inds]).most_common(1)[0][0]
mapping[cluster] = most_common
y_mapped = np.array([mapping[c] for c in y_pred])
return y_mapped, mapping
def clustering_error(y_true, y_pred, n_clusters):
y_mapped, mapping = map_clusters_to_labels(y_true, y_pred, n_clusters)
acc = np.mean(y_mapped == y_true)
err = 1.0 - acc
return err, acc, mapping
# -----------------------
# Загрузка данных
# -----------------------
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
# -----------------------
# Метод локтя: инерция (SSE) для разных k
# -----------------------
inertias = []
for k in K_RANGE:
km = KMeans(n_clusters=k, random_state=RANDOM_STATE, n_init='auto')
km.fit(X)
inertias.append(km.inertia_)
# Сохраняем график локтя
elbow_path = Path(OUT_DIR) / "elbow_scree.png"
plt.figure(figsize=(6,4))
plt.plot(list(K_RANGE), inertias, marker='o')
plt.xticks(list(K_RANGE))
plt.xlabel("k (количество кластеров)")
plt.ylabel("Сумма квадратов внутри кластеров (inertia / SSE)")
plt.title("Метод локтя (Elbow / Scree plot)")
plt.tight_layout()
plt.savefig(elbow_path.as_posix())
plt.close()
PLOTS['elbow'] = elbow_path.as_posix()
# -----------------------
# Silhouette (для k>=2)
# -----------------------
sil_scores = {}
for k in range(2, 8):
km = KMeans(n_clusters=k, random_state=RANDOM_STATE, n_init='auto')
labels = km.fit_predict(X)
s = silhouette_score(X, labels)
sil_scores[k] = s
silhouette_path = Path(OUT_DIR) / "silhouette.png"
plt.figure(figsize=(6,4))
plt.plot(list(sil_scores.keys()), [sil_scores[k] for k in sil_scores], marker='o')
plt.xlabel("k")
plt.ylabel("Средний коэффициент силуэта")
plt.title("Silhouette score vs k")
plt.tight_layout()
plt.savefig(silhouette_path.as_posix())
plt.close()
PLOTS['silhouette'] = silhouette_path.as_posix()
# -----------------------
# Кластеризация по парам (0,1) и (1,2)
# -----------------------
pairs = [
(0,1, "параметры 1 и 2 (features 0 & 1)"),
(1,2, "параметры 2 и 3 (features 1 & 2)")
]
results = []
for idx_pair in pairs:
i, j, desc = idx_pair
X_sub = X[:, [i, j]]
k = 3
km = KMeans(n_clusters=k, random_state=RANDOM_STATE, n_init='auto')
labels = km.fit_predict(X_sub)
err, acc, mapping = clustering_error(y, labels, k)
fname = Path(OUT_DIR) / f"cluster_{i}_{j}.png"
plt.figure(figsize=(6,4))
for cluster_id in range(k):
pts = X_sub[labels == cluster_id]
plt.scatter(pts[:,0], pts[:,1], label=f"cluster {cluster_id}", s=30)
centers = km.cluster_centers_
plt.scatter(centers[:,0], centers[:,1], marker='x', s=100, linewidths=3)
plt.xlabel(feature_names[i])
plt.ylabel(feature_names[j])
plt.title(f"k-means ({desc}) — ошибка кластеризации: {err:.3f}")
plt.legend(loc="best", fontsize="small")
plt.tight_layout()
plt.savefig(fname.as_posix())
plt.close()
PLOTS[f"cluster_{i}_{j}"] = fname.as_posix()
results.append({
"pair": (i,j),
"desc": desc,
"k": k,
"error": err,
"accuracy": acc,
"mapping": mapping,
"plot": fname.as_posix()
})
# -----------------------
# Если нет Screen_1.png — создаём плейсхолдер (не перезаписываем реальный)
# -----------------------
screen1_path = Path(OUT_DIR) / "Screen_1.png"
if not screen1_path.exists():
plt.figure(figsize=(6,3))
plt.text(0.5, 0.5, "Интерфейс запуска (placeholder)\n(добавьте реальный скриншот lab_output/Screen_1.png)",
ha='center', va='center', fontsize=12, wrap=True)
plt.axis('off')
plt.tight_layout()
plt.savefig(screen1_path.as_posix())
plt.close()
PLOTS['screen1'] = screen1_path.as_posix()
# -----------------------
# Генерация Screen_2.png (график окна кластеризации) без plt.show()
# -----------------------
screen2_path = Path(OUT_DIR) / "Screen_2.png"
# используем первую пару
i, j, desc = pairs[0]
X_sub = X[:, [i, j]]
k = 3
km = KMeans(n_clusters=k, random_state=RANDOM_STATE, n_init='auto')
labels = km.fit_predict(X_sub)
plt.figure(figsize=(6,4))
for cluster_id in range(k):
pts = X_sub[labels == cluster_id]
plt.scatter(pts[:,0], pts[:,1], label=f"cluster {cluster_id}", s=30)
centers = km.cluster_centers_
plt.scatter(centers[:,0], centers[:,1], marker='x', s=100, linewidths=3)
plt.xlabel(feature_names[i])
plt.ylabel(feature_names[j])
plt.title(f"k-means ({desc}) — окно кластеризации")
plt.legend(loc="best", fontsize="small")
plt.tight_layout()
plt.savefig(screen2_path.as_posix())
plt.close()
PLOTS['screen2'] = screen2_path.as_posix()
# -----------------------
# Формирование README.md (полный отчёт, чистый Markdown)
# -----------------------
from pathlib import Path as _Path
# подготовим posix-пути для встраивания в Markdown
screen1_md = _Path(OUT_DIR, 'Screen_1.png').as_posix()
screen2_md = _Path(OUT_DIR, 'Screen_2.png').as_posix()
# начало отчёта (восстановленный большой текст)
report_lines = []
report_lines.append("# Лабораторная работа №1 — Кластеризация методом k-средних\n\n")
report_lines.append("> Основано на задании и методических указаниях: \"Кластеризация методом k-средних\" (см. исходный PDF k-means).\n\n")
# 1. Введение
report_lines.append("## 1. Введение (цель, задачи)\n")
report_lines.append("**Цель:** научиться применять алгоритм k-means для кластеризации набора данных и оформлять отчёт по результатам.\n\n")
report_lines.append("**Задачи:**\n")
report_lines.append("- выполнить кластеризацию для набора данных \"Ирисы Фишера\";\n")
report_lines.append("- исследовать выбор числа k (метод локтя, silhouette);\n")
report_lines.append("- проанализировать влияние выбора признаков (пары параметров);\n")
report_lines.append("- оформить отчёт.\n\n")
# 2. Постановка задачи
report_lines.append("## 2. Постановка задачи\n")
report_lines.append("Выполнить кластеризацию методом k-means для набора данных Iris. Произвести кластеризацию для:\n")
report_lines.append("- пары параметров 1 и 2 (features 0 & 1),\n")
report_lines.append("- пары параметров 2 и 3 (features 1 & 2).\n")
report_lines.append("Определить ошибку кластеризации (ошибка = 1 − доля правильно отнесённых объектов после сопоставления кластер→метка).\n\n")
# 3. Средства разработки
report_lines.append("## 3. Средства разработки\n")
report_lines.append("- Python 3.8+,\n")
report_lines.append("- библиотеки: numpy, pandas, scikit-learn, matplotlib.\n")
report_lines.append("(Установите через `pip install numpy pandas scikit-learn matplotlib tabulate`)\n\n")
# 4. Описание системы со скриншотами
report_lines.append("## 4. Описание системы со скриншотами\n")
report_lines.append("Скриншоты интерфейса/запуска/окна программы.\n\n")
report_lines.append("**Описание:** \n")
report_lines.append(f"Программа представляет собой консольный скрипт `lab_kmeans_report.py`, который сохраняет результаты и графики в папке `{OUT_DIR}`.\n\n")
# скриншоты (чистый markdown, подпись под рисунком)
report_lines.append(f" \n")
report_lines.append("*Рисунок 1. Интерфейс запуска / терминал.*\n\n")
report_lines.append(f" \n")
report_lines.append("*Рисунок 2. Окно с графиком кластеризации.*\n\n")
# 5. Оценка результатов — таблица
report_lines.append("## 5. Оценка результатов\n")
report_lines.append("Ниже — результаты кластеризации по парам признаков и метрики:\n\n")
# формируем таблицу через pandas (вставляем markdown-изображения в ячейку "График")
df_rows = []
for r in results:
i, j = r['pair']
plot_posix = _Path(OUT_DIR, Path(r['plot']).name).as_posix()
df_rows.append({
"Пара параметров": f"{i+1} & {j+1} ({feature_names[i]}, {feature_names[j]})",
"k": r['k'],
"Ошибка кластеризации": f"{r['error']:.4f}",
"Точность": f"{r['accuracy']:.4f}",
"График": f""
})
df = pd.DataFrame(df_rows)
report_lines.append(df.to_markdown(index=False))
report_lines.append("\n\n")
# Комментарий
report_lines.append("**Комментарий:**\n")
report_lines.append("- Ошибка по паре параметров 1 и 2 обычно существенно выше, чем по паре 2 и 3 (см. результаты в PDF: ~30% и ~8% соответственно). В этой реализации вы также увидите похожую тенденцию.\n\n")
# 6. Заключение
report_lines.append("## 6. Заключение\n")
report_lines.append("Выполнена кластеризация методом k-means, построены графики метода локтя и силуэта, показано влияние выбора признаков на качество кластеризации.\n\n")
# -----------------------
# Вставка исходного кода скрипта в отчет
# -----------------------
report_lines.append("\n## 7. Исходный код скрипта\n")
report_lines.append("Ниже приведён полный исходный код скрипта `lab_kmeans_report.py`:\n\n")
# Считываем текущий скрипт
script_path = Path(__file__) # путь к текущему файлу
if script_path.exists():
code_text = script_path.read_text(encoding="utf-8")
report_lines.append("```python\n")
report_lines.append(code_text)
report_lines.append("\n```\n")
else:
report_lines.append("_Не удалось вставить исходный код: файл не найден_\n")
# Сгенерированные файлы
report_lines.append(f"## Сгенерированные файлы (в папке {OUT_DIR})\n\n")
for k,v in PLOTS.items():
report_lines.append(f"- {Path(v).name} — {k}\n")
# Запись README.md
report_path = Path("README.md")
report_path.write_text("".join(report_lines), encoding="utf-8")
# -----------------------
# Завершение
# -----------------------
print("Готово. Файлы сохранены в папке:", OUT_DIR)
print("Отчёт:", report_path.as_posix())
for k,v in PLOTS.items():
print(f" - {Path(v).name} -> {v}")
¶ Сгенерированные файлы (в папке lab_output)
- elbow_scree.png — elbow
- silhouette.png — silhouette
- cluster_0_1.png — cluster_0_1
- cluster_1_2.png — cluster_1_2
- Screen_1.png — screen1
- Screen_2.png — screen2